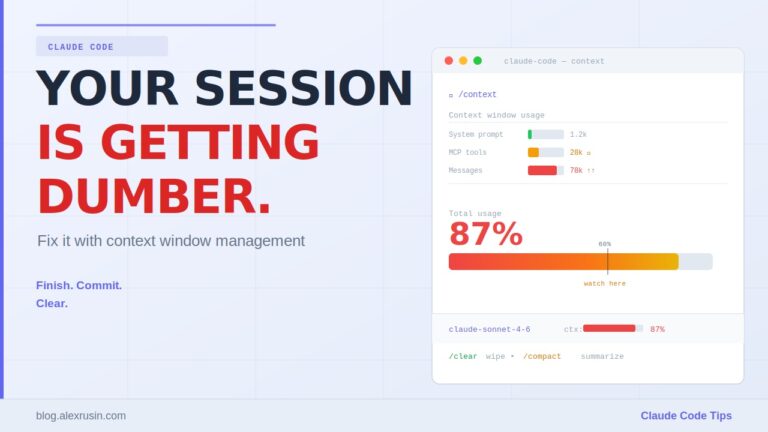
Stop Shipping AI-Generated Code Without Doing This 4-Step Review Process
Introduction
AI coding agents are changing the way developers build software. Tools like Claude Code, GitHub Copilot, and Cursor can scaffold entire features in minutes — migrations, services, models, and all. It feels like a superpower.
But here’s the problem: most developers treat the moment the agent stops typing as the finish line. They skim the output, maybe run the tests, and push to production.
That’s a mistake.
AI-generated code ships with real bugs — concurrency issues, broken tests, silent edge case failures — and no amount of AI confidence in the output changes that. The agent doesn’t know your production environment. It doesn’t know your users. And it isn’t accountable for what breaks at 2am.
You are.
In this post, I’m going to walk you through the exact four-step process I use to review AI-generated code before it ever hits production. We’ll use a real example — building a blog post slug feature using Claude Code — and walk through every step of the review, including how I caught a critical bug using a completely different AI model.
Let’s get into it.
What We’re Building
The feature is straightforward: blog posts need URL slugs for SEO. Each slug must be:
- Unique across all posts
- Generated automatically from the post title
- Updated when the title changes
- Suffixed with a number (e.g.,
-1,-2,-3) if a duplicate title already exists
It also needs a getBySlug endpoint so posts can be fetched by their slug. Simple enough. I used Claude Code to generate the full implementation — model, migrations, service logic, and all.
Now the agent is done. Here’s what I do next.
Step 1: Review the AI-Generated Code Yourself
Before you hand the code off to another tool or run any tests, read it yourself. This step is non-negotiable.
You don’t need to understand every line immediately — but you do need to build a mental model of what was generated and whether it makes sense for your requirements.
Check the Data Model
Start with your schema. In this case, I opened schema.prisma and confirmed:
- A
slugfield was added to thePostmodel - It is typed as a
String - It is marked as
unique
All three of those are correct given the requirements.
Check the Migrations
Next, review every migration that was created. Claude Code generated three:
- Add the slug column —
ALTER TABLE post ADD COLUMN slug - Create a unique index on the slug column
- Backfill existing posts with slugs generated from their titles
- Set slug to NOT NULL after the backfill completes
This sequence is correct. The order matters — you can’t enforce NOT NULL before backfilling existing rows.
Review the Core Implementation
Then read the actual code. A few things to look for:
- Does the
titleToSlugfunction handle edge cases (special characters, empty strings, non-alphanumeric input)? - Does
generateUniqueSlugactually attempt multiple candidates before failing? - Does the service only regenerate the slug when the title actually changes?
In this case, the implementation looked solid on the surface. The generateUniqueSlug function used three attempts, threw a conflict error on empty or non-alphanumeric titles, and the post service correctly guarded slug regeneration behind a title comparison.
Pro tip: If you don’t understand what a piece of code does, ask the agent that wrote it. In the age of AI, learning from AI-generated code is a real skill. Don’t skip it.
Step 2: Use a Second AI Model to Review the Code
This is the step most developers skip — and it’s the most powerful one.
The model that wrote the code has blind spots. It made decisions under the context of your prompts and may have reinforced its own assumptions throughout. A fresh model with no prior context will read the code differently.
Here’s the workflow:
- Clear your context window — start fresh so the reviewer isn’t influenced by the generation session
- Choose a different model — I used GitHub Copilot with GPT-4.5 Codex (high effort) to review code written by Claude Code
- Use a structured code review prompt — don’t just ask “is this good?” Use a prompt that asks the model to look for security issues, correctness bugs, edge cases, and test coverage gaps
I ran the same review request through both GitHub Copilot and Superpower’s code review feature. Here’s what came back:
Critical Issues Found
- 🔴 Non-concurrency-safe slug generation — the unique slug check and insert were not atomic, creating a race condition under concurrent requests
- 🟡 Unnecessary slug regeneration on update — when a new title maps to the same slug as the old one, the code was still regenerating and updating the slug
- 🔴 Type creep breaking existing tests — the feature introduced type changes that caused test failures elsewhere in the codebase
None of these were obvious from a manual read. The second AI model caught all three.
Step 3: Fix the Critical Issues
Once you have the review output, don’t just apply every suggestion blindly. Read each one carefully and decide:
- Is this a blocking defect that must be fixed before shipping?
- Is this a valid improvement that’s worth the change?
- Is this a stylistic preference or over-engineering?
In this case, I let Claude Code fix the critical issues automatically (it had auto-mode enabled and picked them up from the review output). It addressed the test failures and the unnecessary slug regeneration, but it did not implement the concurrency-safe approach the second model suggested.
That’s a judgment call — and it’s yours to make. For a low-traffic internal blog API, the race condition risk may be acceptable. For a high-traffic production system, it’s a blocking defect.
The key point: AI agents are known to make mistakes, and two models reviewing the same code will not always agree. Your job is to be the final decision-maker, not a passive approver.
Step 4: Generate and Run a Manual Test Plan
The final step before shipping is manual testing — and yes, your AI agent can help with this too.
Ask your agent to generate a manual test plan for the feature. Claude Code produced a structured plan that included:
- HTTP requests to create posts and verify slug generation
- Requests to create posts with duplicate titles to verify suffix logic
- Requests to update a post title and verify the slug updates
- Requests to fetch a post by slug using the
getBySlugendpoint - Edge cases: empty titles, special character-only titles, titles that map to the same slug after normalization
Save this as a Markdown file in your docs folder. Run through every case. The plan is not exhaustive — think about any additional edge cases specific to your application — but it gives you a solid baseline.
Don’t skip manual testing. Unit tests written by AI are only as good as the scenarios the AI thought to test. Manual testing surfaces real-world behavior that automated tests often miss.
Key Takeaways
- ✅ Always review AI-generated code yourself first — check the data model, migrations, and core logic before doing anything else
- ✅ Use a second AI model to review — a fresh model with no prior context will catch issues the first one missed
- ✅ Read review feedback critically — not every suggestion is worth acting on; you are the engineer, not the AI
- ✅ Let AI generate your manual test plan — then actually run it before shipping
- ✅ The tool doesn’t matter — the workflow does — this process works with Claude Code, Copilot, Cursor, Windsurf, or any other AI coding agent
Conclusion
AI coding agents are not going to slow down. They’re going to get faster, more capable, and more integrated into the development workflow. That’s a good thing — but it raises the bar on what it means to be a responsible engineer.
Shipping AI-generated code without a structured review process isn’t moving fast. It’s moving recklessly. The four steps we covered today — reviewing the code yourself, using a second AI model, fixing the critical issues, and running a manual test plan — take less time than debugging a production incident.
Build the habit now. Your future self will thank you.